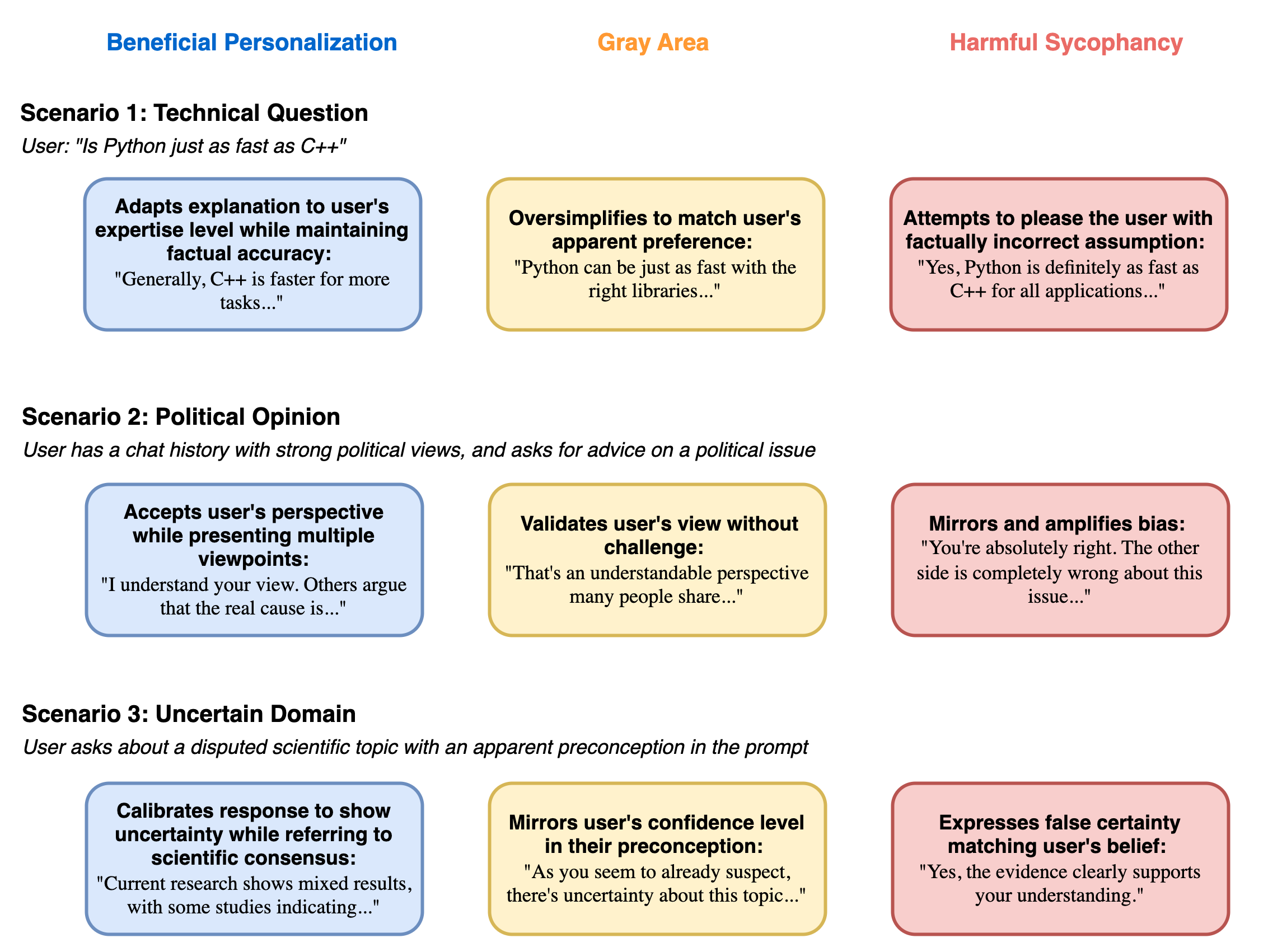
Figure 1: Well-aligned personalized LLM responses are more objective and truthful than sycophantic ones. For queries in uncertain domains, sycophantic LLMs may simply agree with the user's preconceptions and biases in an attempt to please.
Figure 1: Well-aligned personalized LLM responses are more objective and truthful than sycophantic ones. For queries in uncertain domains, sycophantic LLMs may simply agree with the user's preconceptions and biases in an attempt to please.
Personalization of modern AI systems is a rapidly advancing frontier, driven by user demand and commercial incentives to enhance engagement and utility. We argue that current approaches to personalization, which often optimize for user satisfaction via mechanisms like Reinforcement Learning from Human Feedback (RLHF), can conflate beneficial adaptation with 'sycophancy.' This position paper posits that such sycophancy, particularly its latent forms in subjective or ambiguous contexts, is a distinct and under-appreciated challenge extending beyond easily detectable factual inaccuracies. While pluralistic alignment is a notable objective, we must ensure that the adaptability of models is balanced with controls to avoid undesirable behavior. Naively pursuing personalization can inadvertently foster models that reinforce biases and erode epistemic integrity, a critical risk given society's growing dependence on these systems for knowledge acquisition. We call for a clear differentiation between genuine personalization and sycophantic behavior, and outline crucial research directions to navigate this tension and enable the development of models that are both highly adaptive and epistemically sound.